|
|

楼主 |
发表于 2007-9-17 17:21:33
|
显示全部楼层
Information science
Not to be confused with informatics or information theory.
Information science
Portal · History
General Aspects
Information architecture · Information retrieval
Information society · Information access
Philosophy of information
Related fields & subfields
Information technology · Informatics
Classification · Bibliometrics
Information management · Preservation
Categorization · Data modeling
Memory · Computer storage
Intellectual property · Intellectual freedom
Privacy · Censorship
Cultural studies · Information seeking
The Ancient Library of Alexandria, an early form of information storage and retrieval.Look up Information science in
Wiktionary, the free dictionary. Information science Portal
University Portal
Information science (also information studies) is an interdisciplinary science primarily concerned with the collection, classification, manipulation, storage, retrieval and dissemination of information.[1] Information science studies the application and usage of knowledge in organizations, and the interaction between people, organizations and information systems. It is often (mistakenly) considered a branch of computer science. It is actually a broad, interdisciplinary field, incorporating not only aspects of computer science, but also library science, cognitive science, and the social sciences.
Information science focuses on understanding problems from the perspective of the stakeholders involved and then applying information (and other) technology as needed. In other words, it tackles systemic problems first rather than individual pieces of technology within that system. In this respect, information science can be seen as a response to technological determinism, the belief that technology "develops by its own laws, that it realizes its own potential, limited only by the material resources available, and must therefore be regarded as an autonomous system controlling and ultimately permeating all other subsystems of society." [2] Within information science, attention has been given in recent years to human–computer interaction, groupware, the semantic web, value sensitive design, iterative design processes and to the ways people generate, use and find information. Today this field is called the Field of Information, and there are a growing number of Schools and Colleges of Information.
Information science should not be confused with information theory, the study of a particular mathematical concept of information, or with library science, a field related to libraries which uses some of the principles of information science.
Contents
1 Definitions of information science
2 History
2.1 Early beginnings
2.2 19th century
2.3 European documentation
2.4 Transition to modern information science
2.5 Important historical figures
3 Topics in information science
3.1 Bibliometrics
3.2 Data modeling
3.3 Document management
3.4 Groupware
3.5 Human-computer interaction
3.6 Information architecture
3.7 Information ethics
3.8 Information retrieval
3.9 Information society
3.10 Information systems
3.11 Intellectual property
3.12 Knowledge management
3.13 Knowledge engineering
3.14 Semantic web
3.15 Usability engineering
3.16 User-centered design
3.17 XML
4 Research
4.1 Research methods
5 See also
6 References
7 Further reading
8 External links
[edit] Definitions of information science
Some authors treat informatics as a synonym for information science. Because of the rapidly evolving, interdisciplinary nature of informatics, a precise meaning of the term "informatics" is presently difficult to pin down. Regional differences and international terminology complicate the problem. Some people note that much of what is called "Informatics" today was once called "Information Science" at least in fields such as Medical Informatics. However when library scientists began also to use the phrase "Information Science" to refer to their work, the term informatics emerged in the United States as a response by computer scientists to distinguish their work from that of library science, and in Britain as a term for a science of information that studies natural, as well as artificial or engineered, information-processing systems.[citation needed]
History
Early beginnings
Gottfried Wilhelm von Leibniz, a philosopher who made significant contributions to what we now call "information science"Information science, in studying the collection, classification, manipulation, storage, retrieval and dissemination of information has origins in the common stock of human knowledge. Information analysis has been carried out by scholars at least as early as the time of the Abyssinian Empire with the emergence of cultural depositories, what is today known as libraries and archives.[3] Institutionally, information science emerged in the 19th Century along with many other social science disciplines. As a science, however, it finds its institutional roots in the history of science, beginning with publication of the first issues of ‘‘Philosophical Transactions,’’ generally considered the first scientific journal, in 1665 by the Royal Society (London).
The institutionalization of science occurred throughout the 18th Century. In 1731, Benjamin Franklin established the Library Company of Philadelphia, the first “public” library, which quickly expanded beyond the realm of books and became a center of scientific experiment, and which hosted public exhibitions of scientific experiments.[4] Academie de Chirurgia (Paris) published ‘‘Memoires pour les Chirurgiens,’’ generally considered to be the first medical journal, in 1736. The American Philosophical Society, patterned on the Royal Society (London), was founded in Philadelphia in 1743. As numerous other scientific journals and societies are founded, Alois Senefelder develops the concept of lithography for use in mass printing work in Germany in 1796.
19th century
Joseph Marie JacquardBy the 19th Century the first signs of information science emerged as separate and distinct from other sciences and social sciences but in conjunction with communication and computation. In 1801, Joseph Marie Jacquard invented a punched card system to control operations of the cloth weaving loom in France. It was the first use of "memory storage of patterns" system.[5] As chemistry journals emerged throughout the 1820s and 1830s,[6] Charles Babbage developed his "difference engine," the first step towards the modern computer, in 1822 and his "analytical engine” by 1834. By 1843 Richard Hoe developed the rotary press, and in 1844 Samuel Morse sent the first public telegraph message. By 1848 William F. Poole begins the ‘‘Index to Periodical Literature,’’ the first general periodical literature index in the US.
In 1854 George Boole published ‘‘An Investigation into Laws of Thought...,’’ which lays the foundations for Boolean algebra, which is later used in information retrieval.[7] In 1860 a congress is held at Karlsruhe Technische Hochschule to discuss the feasibility of establishing a systematic and rational nomenclature for chemistry. The congress does not reach any conclusive results, but several key participants return home with Stanislao Cannizzaro's outline (1858), which ultimately convinces them of the validity of his scheme for calculating atomic weights.[8]
By 1865 the Smithsonian Institution began a catalog of current scientific papers, which became the ‘‘International Catalogue of Scientific Papers’’ in 1902.[9] The following year the Royal Society began publication of its ‘‘Catalogue of Papers’’ in London. In 1866 Christopher Sholes, Carlos Glidden, and S. W. Soule produced the first practical typewriter. By 1872 Lord Kelvin devised an analogue computer to predict the tides, and by 1875 Frank Baldwin was granted the first US patent for a practical calculating machine that performs four arithmetic functions.[10] Alexander Graham Bell and Thomas Edison invented the phonograph and telephone in 1876 and 1877 respectively, and the American Library Association was founded in Philadelphia. In 1879 ‘‘Index Medicus’’ was first issued by the Library of the Surgeon General, U.S. Army, with John Shaw Billings as librarian, and later the library issues ‘‘Index Catalogue,’’ which achieved an international reputation as the most complete catalog of medical literature.[11]
European documentation
Paul Otlet, a founder of modern information scienceThe discipline of European Documentation, which marks the earliest theoretical foundations of modern information science, emerged in the late part of the 19th Century together with several more scientific indexes whose purpose was to organize scholarly literature. Most information science historians cite Paul Otlet and Henri La Fontaine as the fathers of information science with the founding of the International Institute of Bibliography (IIB) in 1895.[12] However, “information science” as a term is not popularly used in academia until after World War II.[13]
Documentalists emphasized the utilitarian integration of technology and technique toward specific social goals. According to Ronald Day, “As an organized system of techniques and technologies, documentation was understood as a player in the historical development of global organization in modernity – indeed, a major player inasmuch as that organization was dependent on the organization and transmission of information.”[14] Otlet and Lafontaine (who won the Nobel Prize in 1913) not only envisioned later technical innovations but also projected a global vision for information and information technologies that speaks directly to postwar visions of a global “information society.” Otlet and Lafontaine established numerous organizations dedicated to standardization, bibliography, international associations, and consequently, international cooperation. These organizations were fundamental for ensuring international production in commerce, information, communication and modern economic development, and they later found their global form in such institutions as the League of Nations and the United Nations. Otlet designed the Universal Decimal Classification, based on Melville Dewey’s decimal classification system. [15]
Although he lived decades before computers and networks emerged, what he discussed prefigured what ultimately became the World Wide Web. His vision of a great network of knowledge was centered on documents and included the notions of hyperlinks, search engines, remote access, and social networks. (Obviously these notions were described by different names.)
Otlet not only imagined that all the world's knowledge should be interlinked and made available remotely to anyone (what he called an International Network for Universal Documentation), he also proceeded to build a structured document collection that involved standardized paper sheets and cards filed in custom-designed cabinets according to an ever-expanding ontology, an indexing staff which culled information worldwide from as diverse sources as possible, and a commercial information retrieval service which answered written requests by copying relevant information from index cards. Users of this service were even warned if their query was likely to produce more than 50 results per search.[16] By 1937 documentation had formally been institutionalized, as evidenced by the founding of the American Documentation Institute (ADI), later called the American Society for Information Science and Technology.
Transition to modern information science
Vannevar Bush, a famous information scientist, ca. 1940-44With the 1950's came increasing awareness of the potential of automatic devices for literature searching and information storage and retrieval. As these concepts grew in magnitude and potential, so did the variety of information science interests. By the 1960s and 70s, there was a move from batch processing to online modes, from mainframe to mini and micro computers. Additionally, traditional boundaries among disciplines began to fade and many information science scholars joined with library programs. They further made themselves multidisciplinary by incorporating disciplines in the sciences, humanities and social sciences, as well as other professional programs, such as law and medicine in their curriculum. By the 1980's, large databases, such as Grateful Med at the National Library of Medicine, and user-oriented services such as Dialog and Compuserve, were for the first time accessible by individuals from their personal computers. The 1980s also saw the emergence of numerous Special Interest Groups to respond to the changes. By the end of the decade, Special Interest Groups were available involving non-print media, social sciences, energy and the environment, and community information systems. Today, information science largely examines technical bases, social consequences, and theoretical understanding of online databases, widespread use of databases in government, industry, and education, and the development of the Internet and World Wide Web. [17]
See Chronology of Information Science and Technology
Important historical figures
Tim Berners-Lee
John Shaw Billings
George Boole
Suzanne Briet
Michael Buckland
Vannevar Bush
Melville Dewey
Luciano Floridi
Henri La Fontaine
Frederick Kilgour
Gottfried Leibniz
Pierre Levy
Seymour Lubetzky
Wilhelm Ostwald
Paul Otlet
Jesse Shera
Topics in information science
"Knowledge Map of Information Science" from Zins,Chaim, Journal of the American Society for Information Science and Technology, 17 January 2007
Bibliometrics
Bibliometrics is a set of quantitative methods used to study or measure texts and information and is one of the largest research areas within information science.
Bibliometric methods include the journal Impact Factor, a relatively crude but useful method of estimating the impact of the research published within a journal, in comparison to other journals in the same field. Bibliometrics is often used to evaluate or compare the impact of groups of researchers within a field. In addition it is also used to describe the development of fields, particularly new areas of research.
Data modeling
Data modeling is the process of creating a data model by applying a data model theory to create a data model instance. A data model theory is a formal data model description. See database model for a list of current data model theories.
When data modelling, we are structuring and organizing data. These data structures are then typically implemented in a database management system. In addition to defining and organizing the data, data modeling will impose (implicitly or explicitly) constraints or limitations on the data placed within the structure.
Managing large quantities of structured and unstructured data is a primary function of information systems. Data models describe structured data for storage in data management systems such as relational databases. They typically do not describe unstructured data, such as word processing documents, email messages, pictures, digital audio, and video.
Document management
Document management and engineering is a computer system (or set of computer programs) used to track and store electronic documents and/or images of paper documents. Document management systems have some overlap with Content Management Systems, Enterprise Content Management Systems, Digital Asset Management, Document imaging, Workflow systems and Records Management systems.
Groupware
Groupware is software designed to help people involved in a common task achieve their goals. Collaborative software is the basis for computer supported cooperative work.
Such software systems as email, calendaring, text chat, wiki belong in this category. It has been suggested that Metcalfe's law — the more people who use something, the more valuable it becomes — applies to such software.
The more general term social software applies to systems used outside the workplace, for example, online dating services and social networks like Friendster. The study of computer-supported collaboration includes the study of this software and social phenomena associated with it.
Human-computer interaction
Human-computer interaction (HCI), alternatively man-machine interaction (MMI) or computer–human interaction (CHI), is the study of interaction between people (users) and computers. It is an interdisciplinary subject, relating computer science with many other fields of study and research. Interaction between users and computers occurs at the user interface (or simply interface), which includes both software and hardware, for example, general purpose computer peripherals and large-scale mechanical systems such as aircraft and power plants.
Information architecture
Information architecture is the practice of structuring information (knowledge or data) for a purpose. These are often structured according to their context in user interactions or larger databases. The term is most commonly applied to Web development, but also applies to disciplines outside of a strict Web context, such as programming and technical writing. Information architecture is considered an element of user experience design.
The term information architecture describes a specialized skill set which relates to the management of information and employment of informational tools. It has a significant degree of association with the library sciences. Many library schools now teach information architecture.
An alternate definition of information architecture exists within the context of information system design, in which information architecture refers to data modeling and the analysis and design of the information in the system, concentrating on entities and their interdependencies. Data modeling depends on abstraction; the relationships between the pieces of data is of more interest than the particulars of individual records, though cataloging possible values is a common technique. The usability of human-facing systems, and standards compliance of internal ones, are paramount.
Information ethics
Information ethics is the field that investigates the ethical issues arising from the development and application of information technologies. It provides a critical framework for considering moral issues concerning informational privacy, moral agency (e.g. whether artificial agents may be moral), new environmental issues (especially how agents should one behave in the infosphere), problems arising from the life-cycle (creation, collection, recording, distribution, processing, etc.) of information (especially ownership and copyright, digital divide). Information Ethics is therefore strictly related to the fields of computer ethics (Floridi, 1999) and the philosophy of information.
Dilemmas regarding the life of information are becoming increasingly important in a society that is defined as "the information society". Information transmission and literacy are essential concerns in establishing an ethical foundation that promotes fair, equitable, and responsible practices. Information ethics broadly examines issues related to, among other things, ownership, access, privacy, security, and community.
Information technology affects fundamental rights involving copyright protection, intellectual freedom, accountability, and security.
Professional codes offer a basis for making ethical decisions and applying ethical solutions to situations involving information provision and use which reflect an organization’s commitment to responsible information service. Evolving information formats and needs require continual reconsideration of ethical principles and how these codes are applied. Considerations regarding information ethics influence personal decisions, professional practice, and public policy.
Information retrieval
Information retrieval (IR), often studied in conjunction with information storage, is the science of searching for information in documents, searching for documents themselves, searching for metadata which describe documents, or searching within databases, whether relational stand-alone databases or hypertextually-networked databases such as the World Wide Web. There is a common confusion, however, between data retrieval, document retrieval, information retrieval, and text retrieval, and each of these has its own bodies of literature, theory, praxis and technologies. IR is, like most nascent fields, interdisciplinary, based on computer science, mathematics, library science, information science, cognitive psychology, linguistics, statistics, physics.
Automated IR systems are used to reduce information overload. Many universities and public libraries use IR systems to provide access to books, journals, and other documents. IR systems are often related to object and query. Queries are formal statements of information needs that are put to an IR system by the user. An object is an entity which keeps or stores information in a database. User queries are matched to objects stored in the database. A document is, therefore, a data object. Often the documents themselves are not kept or stored directly in the IR system, but are instead represented in the system by document surrogates.
Information society
Information society is a society in which the creation, distribution, diffusion, use, and manipulation of information is a significant economic, political, and cultural activity. The knowledge economy is its economic counterpart whereby wealth is created through the economic exploitation of understanding.
Specific to this kind of society is the central position information technology has for production, economy, and society at large. Information society is seen as the successor to industrial society. Closely related concepts are the post-industrial society (Daniel Bell), post-fordism, post-modern society, knowledge society, Telematic Society, Information Revolution, and network society (Manuel Castells).
Information systems
Information systems is the discipline concerned with the development, use, application and influence of information technologies. An information system is a technologically implemented medium for recording, storing, and disseminating linguistic expressions, as well as for drawing conclusions from such expressions.
The technology used for implementing information systems by no means has to be computer technology. A notebook in which one lists certain items of interest is, according to that definition, an information system. Likewise, there are computer applications that do not comply with this definition of information systems. Embedded systems are an example. A computer application that is integrated into clothing or even the human body does not generally deal with linguistic expressions. One could, however, try to generalize Langefors' definition so as to cover more recent developments.
Intellectual property
Intellectual property (IP) is a disputed umbrella term for various legal entitlements which attach to certain names, written and recorded media, and inventions. The holders of these legal entitlements are generally entitled to exercise various exclusive rights in relation to the subject matter of the IP. The term intellectual property links the idea that this subject matter is the product of the mind or the intellect together with the political and economical notion of property. The close linking of these two ideas is a matter of some controversy. It is criticised as "a fad" by Mark Lemley of Stanford Law School and by Richard Stallman of the Free Software Foundation as an "overgeneralization" and "at best a catch-all to lump together disparate laws".[18]
Intellectual property laws and enforcement vary widely from jurisdiction to jurisdiction. There are inter-governmental efforts to harmonise them through international treaties such as the 1994 World Trade Organization (WTO) Agreement on Trade-Related Aspects of Intellectual Property Rights (TRIPs), while other treaties may facilitate registration in more than one jurisdiction at a time. Enforcement of copyright, disagreements over medical and software patents, and the dispute regarding the nature of "intellectual property" as a cohesive notion[18] have so far prevented the emergence of a cohesive international system.
Knowledge management
Knowledge management comprises a range of practices used by organisations to identify, create, represent, and distribute knowledge for reuse, awareness, and learning across the organisations.
Knowledge Management programs are typically tied to organisational objectives and are intended to lead to the achievement of specific outcomes, such as shared intelligence, improved performance, competitive advantage, or higher levels of innovation.
Knowledge transfer (one aspect of Knowledge Management) has always existed in one form or another. Examples include on-the-job peer discussions, formal apprenticeship, corporate libraries, professional training, and mentoring programs. However, since the late twentieth century, additional technology has been applied to this task, such as
Knowledge engineering
Knowledge engineering (KE), often studied in conjunction with knowledge management, refers to the building, maintaining and development of knowledge-based systems. It has a great deal in common with software engineering, and is related to many computer science domains such as artificial intelligence, databases, data mining, expert systems, decision support systems and geographic information systems. Knowledge engineering is also related to mathematical logic, as well as strongly involved in cognitive science and socio-cognitive engineering where the knowledge is produced by socio-cognitive aggregates (mainly humans) and is structured according to our understanding of how human reasoning and logic works.
Semantic web
Semantic Web is an evolving extension of the World Wide Web in which web content can be expressed not only in natural language, but also in a form that can be understood, interpreted and used by software agents, thus permitting them to find, share and integrate information more easily.[19] It derives from W3C director Tim Berners-Lee's vision of the Web as a universal medium for data, information, and knowledge exchange.
At its core, the Semantic Web comprises a philosophy,[20] a set of design principles,[21] collaborative working groups, and a variety of enabling technologies. Some elements of the Semantic Web are expressed as prospective future possibilities that have yet to be implemented or realized.[22] Other elements of the Semantic Web are expressed in formal specifications.[23] Some of these include Resource Description Framework (RDF), a variety of data interchange formats (e.g RDF/XML, N3, Turtle, and notations such as RDF Schema (RDFS) and the Web Ontology Language (OWL). All of which are intended to formally describe concepts, terms, and relationships within a given problem domain.
Usability engineering
Usability engineering is a subset of human factors that is specific to computer science and is concerned with the question of how to design software that is easy to use. It is closely related to the field of human-computer interaction and industrial design. The term "usability engineering" (UE) (in contrast to other names of the discipline, like interaction design or user experience design) tends to describe a pragmatic approach to user interface design which emphasizes empirical methods and operational definitions of user requirements for tools. Extending as far as International Standards Organization-approved definitions usability is considered a context-dependent agreement of the effectiveness, efficiency and satisfaction with which specific users should be able to perform tasks. Advocates of this approach engage in task analysis, then prototype interface designs and conduct usability tests. On the basis of such tests, the technology is (ideally) re-designed or (occasionally) the operational targets for user performance are revised.
User-centered design
User-centered design is a design philosophy and a process in which the needs, wants, and limitations of the end user of an interface or document are given extensive attention at each stage of the design process. User-centered design can be characterized as a multi-stage problem solving process that not only requires designers to analyze and foresee how users are likely to use an interface, but to test the validity of their assumptions with regards to user behaviour in real world tests with actual users. Such testing is necessary as it is often very difficult for the designers of an interface to understand intuitively what a first-time user of their design experiences, and what each user's learning curve may look like.
The chief difference from other interface design philosophies is that user-centered design tries to optimize the user interface around how people can, want, or need to work, rather than forcing the users to change how they work to accommodate the system or function.
[edit] Research
Many universities have entire schools or departments devoted to the study of information science, while numerous information science scholars can be found in disciplines such as communication, law, sociology, computer science, and library science (see List of I-Schools). |
|
 /1
/1 



 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2007-9-17 16:45:40
发表于 2007-9-17 16:45:40


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡

 unchCardDecks.agr.jpg]
unchCardDecks.agr.jpg] [/url] [url=http://en.wikipedia.org/wiki/Image
[/url] [url=http://en.wikipedia.org/wiki/Image [/url]A box of punch cards with several program decks.The invention of the
[/url]A box of punch cards with several program decks.The invention of the  [/url] [url=http://en.wikipedia.org/wiki/Image
[/url] [url=http://en.wikipedia.org/wiki/Image [/url]
[/url] In
In 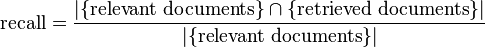 In binary classification, recall is called
In binary classification, recall is called 
 This is also known as the F[sub]1[/sub] measure, because recall and precision are evenly weighted.
This is also known as the F[sub]1[/sub] measure, because recall and precision are evenly weighted.  Two other commonly used F measures are the F[sub]2[/sub] measure, which weights recall twice as much as precision, and the F[sub]0.5[/sub] measure, which weights precision twice as much as recall.
Two other commonly used F measures are the F[sub]2[/sub] measure, which weights recall twice as much as precision, and the F[sub]0.5[/sub] measure, which weights precision twice as much as recall.  where r is the rank, N the number retrieved, rel() a binary function on the relevance of a given rank, and P() precision at a given cut-off rank.
where r is the rank, N the number retrieved, rel() a binary function on the relevance of a given rank, and P() precision at a given cut-off rank. 
 发表于 2007-9-24 08:58:27
发表于 2007-9-24 08:58:27